本文由博主原创,转载请注明出处
git爬虫项目地址(关注和star在哪里~~):https://github.com/MatrixSeven/ZhihuSpider
咱们上一篇所长说了爬虫的爬取大概思路,这一篇幅就来研究分析下模拟登陆知乎.
首先来说,网上模拟登陆知乎的文章已经是多不胜数,而且模拟登陆知乎也比模拟登陆微博百度简单很多,但是本着善始善终的原则,咱们还是重头到尾的过上一遍.
1.工具
恩,工具呢,就用咱们自己平时用的浏览器就ok.牛逼闪闪的f12,就足够用.然后在使用下Fiddler来查看下登陆状态…
2.登陆分析
打开www.zhihu.com,点击登陆,然后直接F12,调试出开发者工具,选择NetWork,输入账号 密码 和验证码,点击登陆,发现右侧出现了网络请求.
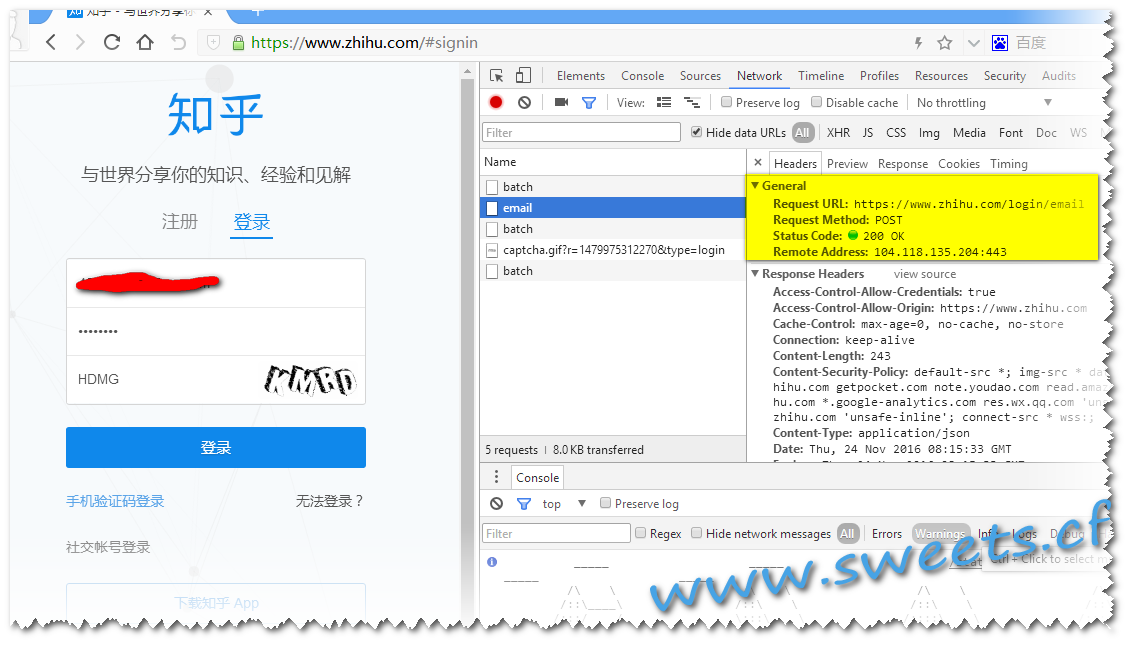
发现有个email的请求,请求信息为:
请求地址:https://www.zhihu.com/login/email
请求方式:post
下面的内容先不去管它,直接拽到最下面
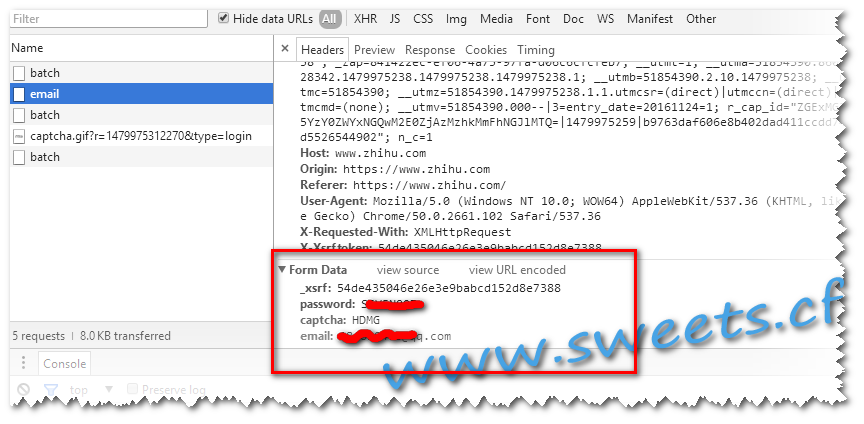
..发现有如下信息
_xsrf:xxxxxxxxxxxxxxxxxx
password:xxxxx
captcha:HDMG
email:xxxxxx@xx.com
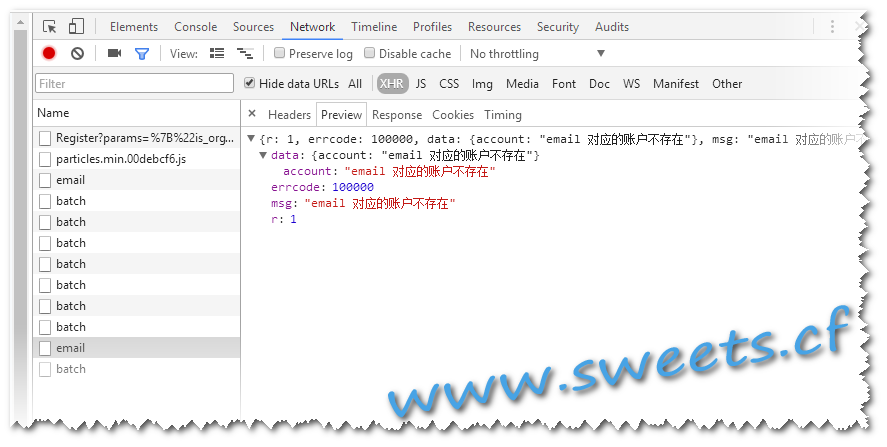
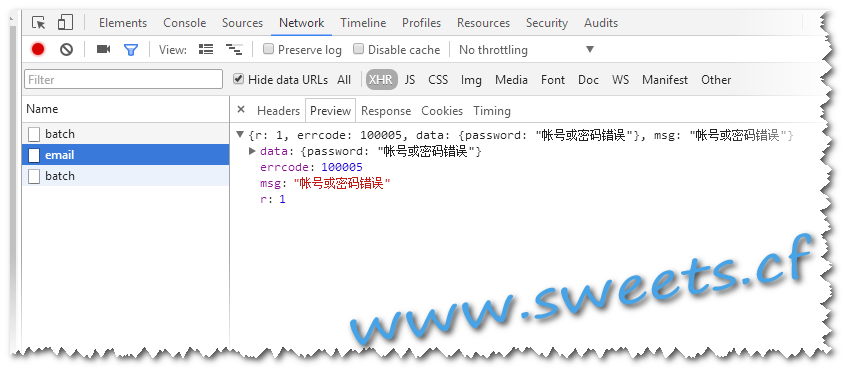
恩,就是Post一下,看看登陆时候成功,并且抓一下登陆失败时的错误信息. 故意输入错误邮箱 ,密码 拿到如下结果:
- 邮箱不存在:
- 密码错误:
那么登陆成功是怎么一种标识状态呢?
咱们这里借助下Fiddler
打开Fiddler,再次进项知乎登陆,然后找到 https://www.zhihu.com/login/email 这个请求.发现登陆成功后返回了一个Json串:
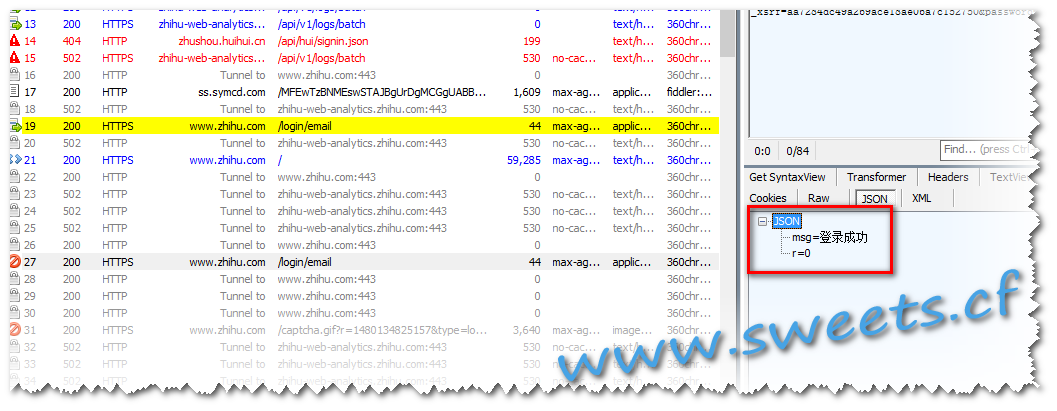
恩,那么还有一个_xsrf,那么这个参数在哪里呢?
其实_xsrf这种东西,基本都存在于页面的源码里,打开登陆页面,右键查看查看源代码,可发现:
 哈哈,原来在一个隐藏域里….
哈哈,原来在一个隐藏域里….
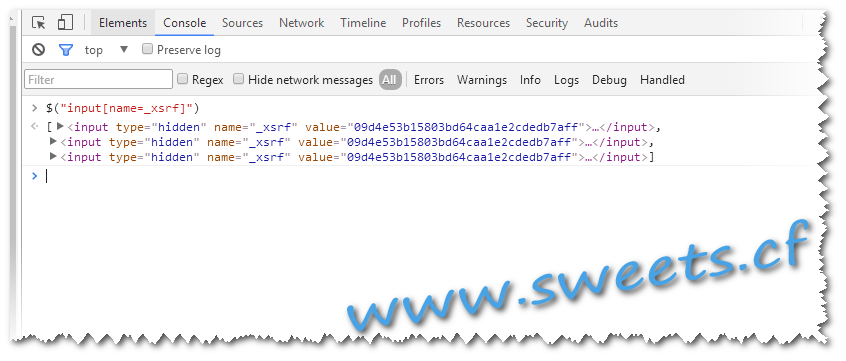
哈哈,这是不是故意就让人爬的了…过程比我想象中的简单很多.. 但是具体行不行呢,还得上代码试一试哈哈…
3.跟随/关注分析
直接打开https://www.zhihu.com/people/Sweets07/followers,然后f12,开始分析请求. 直接滚动页面,发现出现异步请求,请求地址为:
https://www.zhihu.com/api/v4/members/Sweets07/followers?per_page=10&include=data%5B%2A%5D.employments%2Ccover_url%2Callow_message%2Canswer_count%2Carticles_count%2Cfavorite_count%2Cfollower_count%2Cgender%2Cis_followed%2Cmessage_thread_token%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer%29%5D.topics&limit=10&offset=30
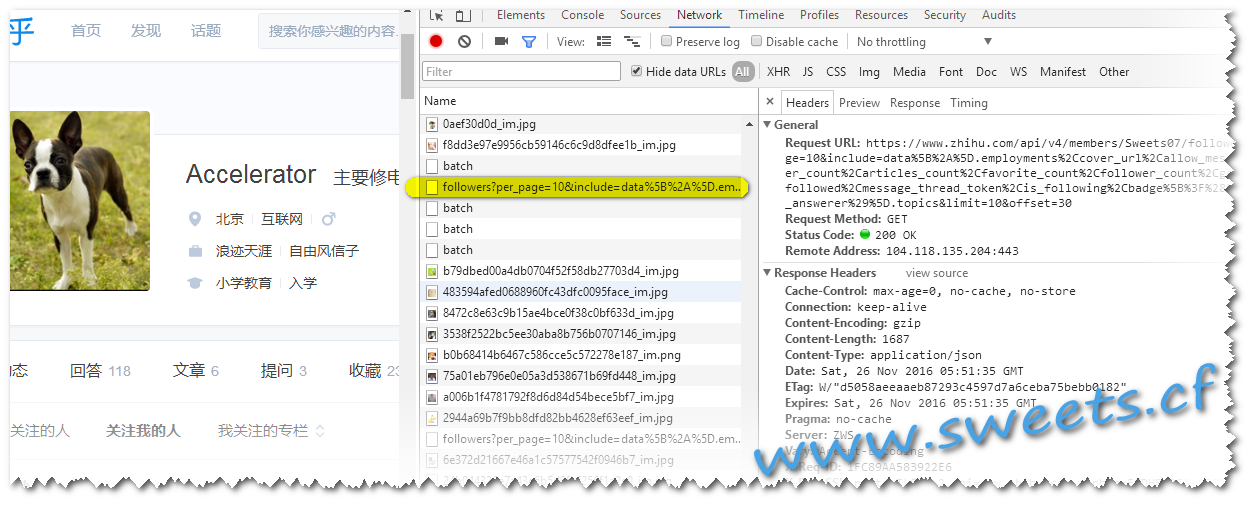
可发现请求参数为:
per_page:10
include:data[*].employments,cover_url,allow_message,answer_count,articles_count,favorite_count,follower_count,gender,is_followed,message_thread_token,is_following,badge[?(type=best_answerer)].topics
limit:10
offset:30
返回的Json为:
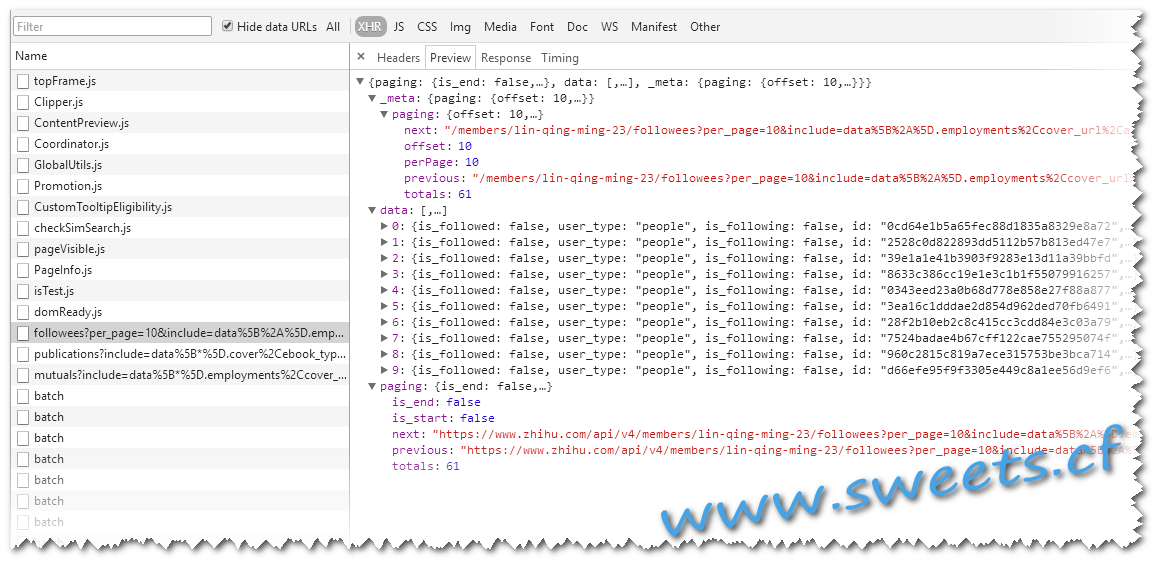
哇塞.里面有各种信息… 如: 1. 下一个请求的地址 2. 人员信息,id啊,头像啊,学校,公司,签名啊,关注人数….. 恩,其实咱们拿一部分就够了,对,就是那个ID…有的id就可以直接打开个人页面了..
然后说这个请求有些问题,因为直接带着cookie get会出现一个错误:
{"message":"身份未经过验证","code":100,"name":"AuthenticationException"}
这个是因为在请求的时候多了一个头:
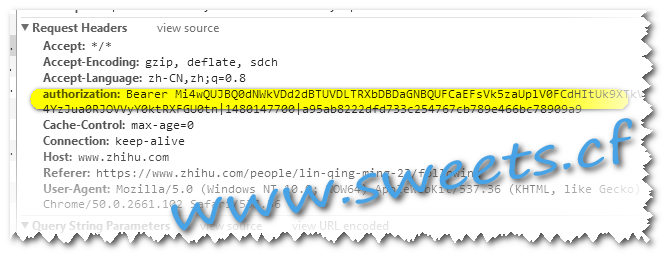
那么这个参数在哪里呢??
找来找去,最后发现,这个参数在请求个人主页信息的cookie里.
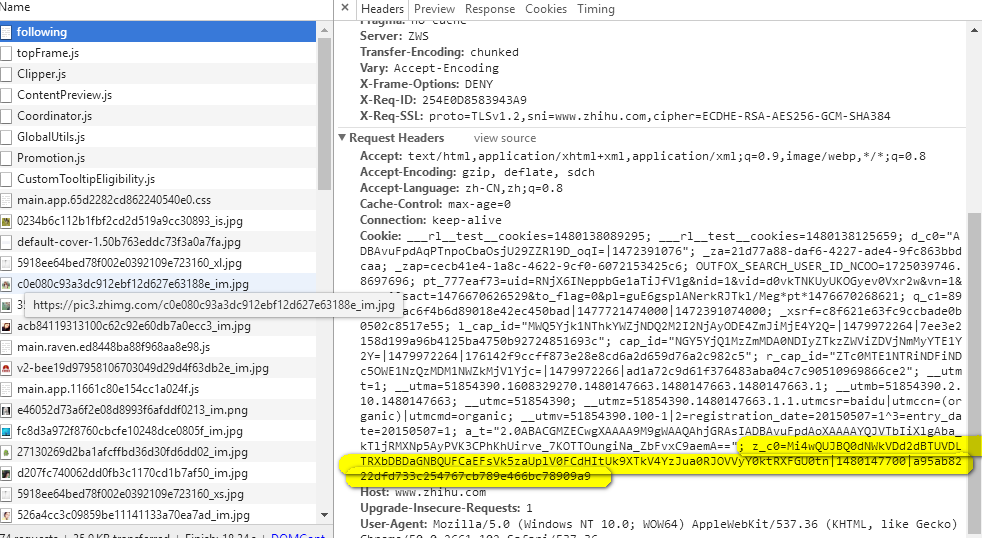
跟随者和关注者差不多…..
就到这里吧,下一步开始撸代码…
//吾爱Java(QQ群):170936712(点击加入)